Supervised Learning là gì?
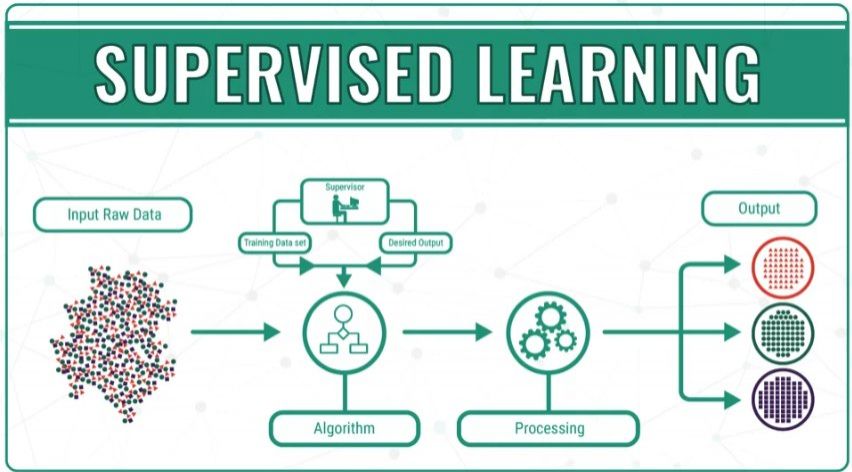
Cách thức học của mô hình Supervised Learning
Supervised Learning (học có giám sát) là nhóm phổ biến nhất trong các thuật toán Machine Learning, trong đó mô hình được huấn luyện dựa trên tập dữ liệu có nhãn, tức là mỗi mẫu dữ liệu đều có thông tin về đầu vào và đầu ra tương ứng. Mục tiêu chính của Supervised Learning là học từ dữ liệu đã được gắn nhãn để đào tạo các thuật toán nhằm phân loại dữ liệu hoặc dự đoán kết quả một cách chính xác.
Ví dụ
Một ứng dụng phổ biến của Supervised Learning là trong nhận diện khuôn mặt trên các nền tảng mạng xã hội. Ví dụ, khi Facebook yêu cầu người dùng gắn thẻ bạn bè vào các bức ảnh, họ sử dụng dữ liệu đã được gắn nhãn (khuôn mặt và tên của bạn bè) để huấn luyện mô hình. Khi lượng dữ liệu đủ lớn, mô hình có thể tự động gợi ý gắn thẻ chính xác.
Một ví dụ khác là trong các hệ thống dự báo thời tiết. Mô hình sử dụng dữ liệu quá khứ như nhiệt độ, độ ẩm và áp suất không khí (dữ liệu đầu vào) cùng với thông tin về thời tiết đã xảy ra (kết quả đầu ra) để dự đoán thời tiết tương lai.
Supervised Learning có thể được chia thành hai loại vấn đề khi khai thác dữ liệu - phân loại và hồi quy:
-
Classification (Phân loại) sử dụng thuật toán để gán chính xác dữ liệu thử nghiệm vào các danh mục cụ thể. Nó nhận ra các thực thể cụ thể trong tập dữ liệu và cố gắng đưa ra một số kết luận về cách các thực thể đó nên được gắn nhãn hoặc xác định, chia thành một số hữu hạn nhóm.
-
Regression (Hồi quy) được sử dụng để hiểu mối quan hệ giữa các biến phụ thuộc và độc lập. Hồi quy là khi biến đầu ra là một giá trị thực cụ thể, chẳng hạn như “đơn vị đô la” hoặc “trọng lượng”. Nó thường được sử dụng để đưa ra các dự đoán, chẳng hạn như doanh thu bán hàng cho một doanh nghiệp nhất định.
Thuật toán Supervised Learning còn được tiếp tục chia nhỏ thành:
-
Hồi quy tuyến tính
-
Hồi quy logistic
-
Phân loại
-
Naive Bayes Classifier
-
K-nearest neighbors
-
Cây quyết định
-
Support Vector Machine
Khi sử dụng mô hình Supervised Learning, ta cần chú ý phương sai và độ lệch chuẩn, các số liệu có ý nghĩa thống kê.
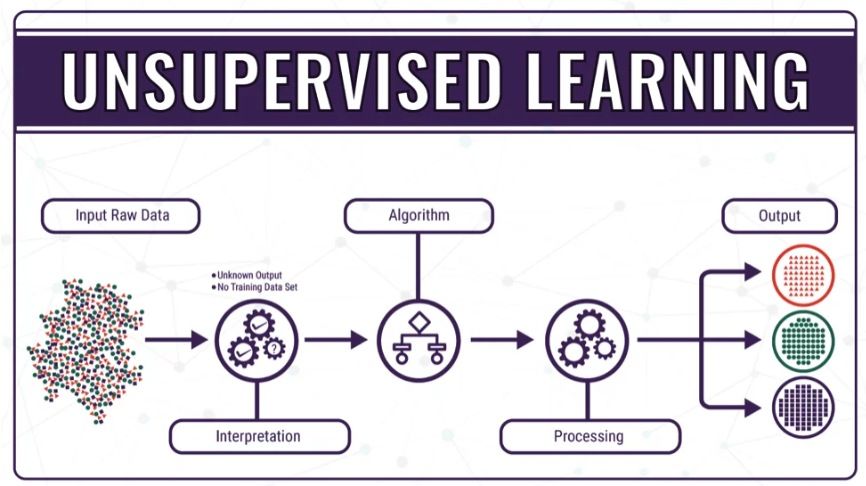
Unsupervised Learning là gì?
Unsupervised Learning (học không giám sát) là một phương pháp Machine Learning mà mô hình không được cung cấp dữ liệu có nhãn. Điều này có nghĩa là chỉ có dữ liệu đầu vào và không có thông tin về kết quả tương ứng. Mục tiêu của Unsupervised Learning là phát hiện các mẫu hoặc mối quan hệ tiềm ẩn trong dữ liệu mà không cần biết trước nhãn hoặc kết quả.
Unsupervised Learning chia thành 2 phương pháp quan trọng trong việc khám phá dữ liệu cấu trúc của người dùng:
-
Clustering (Phân cụm) là một kỹ thuật để khám phá dữ liệu thô, chưa được gắn nhãn và chia nó thành các nhóm (hoặc cụm) dựa trên những điểm tương đồng hoặc khác biệt. Nó được sử dụng trong nhiều ứng dụng, bao gồm phân khúc khách hàng, phát hiện gian lận và phân tích hình ảnh. Các thuật toán phân cụm chia dữ liệu thành các nhóm tự nhiên bằng cách tìm các cấu trúc hoặc mẫu tương tự trong dữ liệu chưa được phân loại.
-
Association (Liên kết) là một cách tiếp cận dựa trên quy tắc để khám phá mối quan hệ thú vị giữa các điểm dữ liệu trong bộ dữ liệu lớn. Các thuật toán học không giám sát tìm kiếm các liên kết để khám phá các mối tương quan và sự xuất hiện đồng thời trong dữ liệu cùng các kết nối khác nhau giữa các đối tượng dữ liệu.
Ví dụ
Phương pháp liên kết này được sử dụng phổ biến nhất để phân tích giỏ bán lẻ hoặc bộ dữ liệu giao dịch để thể hiện tần suất mua một số mặt hàng nhất định cùng nhau. Các thuật toán này khám phá các mô hình mua hàng của khách hàng và các mối quan hệ ẩn giấu trước đây giữa các sản phẩm, giúp cung cấp thông tin cho các công cụ đề xuất hoặc các cơ hội bán kèm khác.
Cách thức học của mô hình Unsupervised Learning
Thay vì dự đoán một kết quả cụ thể, Unsupervised Learning tập trung vào việc tìm ra cấu trúc tiềm ẩn của dữ liệu, chẳng hạn như phân cụm (clustering) hoặc các mẫu trong dữ liệu. Phương pháp này phù hợp trong những trường hợp không có sẵn dữ liệu gắn nhãn.
Một ví dụ điển hình của Unsupervised Learning là phân cụm khách hàng. Doanh nghiệp có thể sử dụng dữ liệu mua sắm của khách hàng mà không cần biết chính xác nhãn của mỗi khách hàng. Thuật toán sẽ tự động phân chia khách hàng thành các nhóm dựa trên hành vi mua hàng, giúp doanh nghiệp cá nhân hóa các chiến dịch tiếp thị.
Trong lĩnh vực bảo mật, Unsupervised Learning có thể được dùng để phát hiện các hoạt động bất thường trên mạng lưới. Bằng cách phân tích các luồng dữ liệu, mô hình có thể tự động nhận diện những hoạt động không bình thường mà không cần biết trước đó là gì.
So sánh sự khác nhau giữa Supervised Learning và Unsupervised Learning
|
Tiêu chí
|
Supervised Learning
|
Unsupervised Learning
|
|
Dữ liệu
|
Sử dụng dữ liệu có nhãn, nghĩa là mỗi điểm dữ liệu có kết quả đầu ra tương ứng
|
Sử dụng dữ liệu không có nhãn, không có thông tin về kết quả đầu ra
|
|
Cách thức học
|
Học từ dữ liệu để dự đoán chính xác kết quả cho dữ liệu mới
|
Phát hiện các cấu trúc hoặc mẫu tiềm ẩn trong dữ liệu không có nhãn
|
|
Ứng dụng
|
Dự đoán kết quả, phân loại (classification), hồi quy (regression)
|
Phân cụm (clustering), phát hiện mẫu, giảm kích thước dữ liệu
|
|
Độ chính xác
|
Độ chính xác cao do dữ liệu có nhãn
|
Kết quả có thể ít chính xác hơn do không có nhãn để đối chiếu
|
|
Yêu cầu dữ liệu
|
Yêu cầu có sẵn dữ liệu gắn nhãn rõ ràng
|
Không yêu cầu dữ liệu gắn nhãn, tiết kiệm thời gian gắn nhãn
|
Nên chọn Supervised hay Unsupervised Learning?
Dữ liệu có gắn nhãn hay không?
Nếu bạn có sẵn một lượng lớn dữ liệu đã được gắn nhãn, Supervised Learning là lựa chọn phù hợp. Đây là phương pháp tối ưu khi bạn muốn dự đoán chính xác cho các trường hợp mới, ví dụ như phân loại hình ảnh, dự đoán giá nhà, hoặc phát hiện email spam.
Ngược lại, nếu bạn không có dữ liệu gắn nhãn hoặc dữ liệu không rõ ràng, Unsupervised Learning sẽ là lựa chọn tối ưu. Nó phù hợp với các bài toán cần khám phá dữ liệu, như phân đoạn khách hàng hoặc phát hiện các mẫu ẩn trong tập dữ liệu lớn.
Mục tiêu của bạn là gì?
-
Supervised Learning là lựa chọn lý tưởng nếu mục tiêu của bạn là xây dựng mô hình dự đoán chính xác, chẳng hạn như phát hiện gian lận hoặc dự đoán xu hướng tiêu dùng.
-
Unsupervised Learning sẽ phù hợp hơn nếu mục tiêu của bạn là khám phá các mẫu tiềm ẩn hoặc tìm hiểu cấu trúc của dữ liệu mà chưa rõ đầu ra, như phân cụm hoặc phát hiện các xu hướng mới.
Kinh nghiệm và nguồn lực
Supervised Learning yêu cầu dữ liệu được gắn nhãn, vì vậy nó tốn kém và mất thời gian để gắn nhãn dữ liệu nếu không có sẵn. Unsupervised Learning không yêu cầu gắn nhãn dữ liệu, giúp giảm chi phí nhưng có thể ít chính xác hơn do không có nhãn để kiểm tra độ chính xác.
Supervised Learning và Unsupervised Learning đều có vai trò quan trọng trong các ứng dụng AI. Việc lựa chọn phương pháp nào tùy thuộc vào loại dữ liệu bạn có và mục tiêu cụ thể của dự án. Nếu bạn có dữ liệu gắn nhãn và cần dự đoán chính xác, hãy chọn Supervised Learning. Ngược lại, nếu bạn muốn khám phá cấu trúc tiềm ẩn của dữ liệu chưa được gắn nhãn, Unsupervised Learning sẽ là lựa chọn tối ưu.
Trên đây là chia sẻ của Vinalink Academy về khái niệm Supervised Learning và Unsupervised Learning trong Machine Learning. Hy vọng những thông tin này sẽ giúp bạn hiểu rõ hơn và có thể áp dụng 2 phương pháp này vào các dự án của mình một cách hiệu quả.. Nếu bạn muốn biết thêm những kiến thức gì về lĩnh vực AI hay Digital Marketing, đừng ngần ngại để lại bình luận phía dưới để chúng tôi cung cấp thêm kiến thức hữu ích cho bạn.
Bạn muốn trở thành chuyên gia huấn luyện AI?
Khóa đào tạo nghề huấn luyện AI Trainer của Vinalink Academy sẽ trang bị cho bạn những kiến thức và kỹ năng chuyên sâu về trí tuệ nhân tạo, đặc biệt là hai phương pháp học máy cốt lõi: Supervised Learning và Unsupervised Learning. Qua khóa học, bạn sẽ nắm vững cách xây dựng và huấn luyện các mô hình AI, từ đó ứng dụng vào giải quyết các bài toán thực tế trong nhiều lĩnh vực khác nhau. Với đội ngũ giảng viên giàu kinh nghiệm và chương trình học được cập nhật liên tục, khóa học sẽ là bước đệm vững chắc giúp bạn trở thành một AI Trainer chuyên nghiệp.
Đăng ký khoá học tại: https://vinalink.edu.vn/khoa-dao-tao-nghe-huan-luyen-ai-trainer/
Một số điểm nổi bật của khóa học:
-
Kiến thức toàn diện: Từ nền tảng lý thuyết đến các kỹ thuật ứng dụng thực tế.
-
Thực hành thực tế: Xây dựng các dự án AI thực tế để củng cố kiến thức.
-
Đội ngũ giảng viên: Các chuyên gia hàng đầu trong lĩnh vực AI.
-
Cộng đồng học tập: Kết nối với các học viên khác và chia sẻ kinh nghiệm.
Đừng bỏ lỡ cơ hội trở thành chuyên gia AI!


 (1)_cr_400x210.png)





_cr_400x210.png)
