Claude Opus 4.7 là gì và ra mắt khi nào?
Claude Opus 4.7 là mô hình ngôn ngữ lớn (LLM) mới nhất của Anthropic, chính thức phát hành ngày 16/04/2026. Đây là bản nâng cấp trực tiếp từ Opus 4.6, tập trung vào ba mảng cải tiến chính: kỹ thuật phần mềm, xử lý hình ảnh và độ tin cậy trong các tác vụ agentic dài hạn.
Điểm khác biệt lớn nhất so với thế hệ trước? Opus 4.7 có khả năng tự kiểm tra và xác thực đầu ra trước khi báo cáo kết quả - tức là thay vì chờ người dùng phát hiện lỗi, mô hình sẽ tự rà soát logic trước. Điều này đặc biệt có giá trị trong môi trường production, nơi mà một lỗi nhỏ có thể gây hậu quả lớn.
Opus 4.7 thuộc dòng model nào của Anthropic?
Anthropic hiện có ba dòng model chính:
- Claude Haiku: Nhẹ, nhanh, chi phí thấp - phù hợp cho tác vụ đơn giản
- Claude Sonnet: Cân bằng giữa hiệu suất và chi phí
- Claude Opus: Mạnh nhất trong gia đình, dành cho tác vụ phức tạp đòi hỏi suy luận sâu
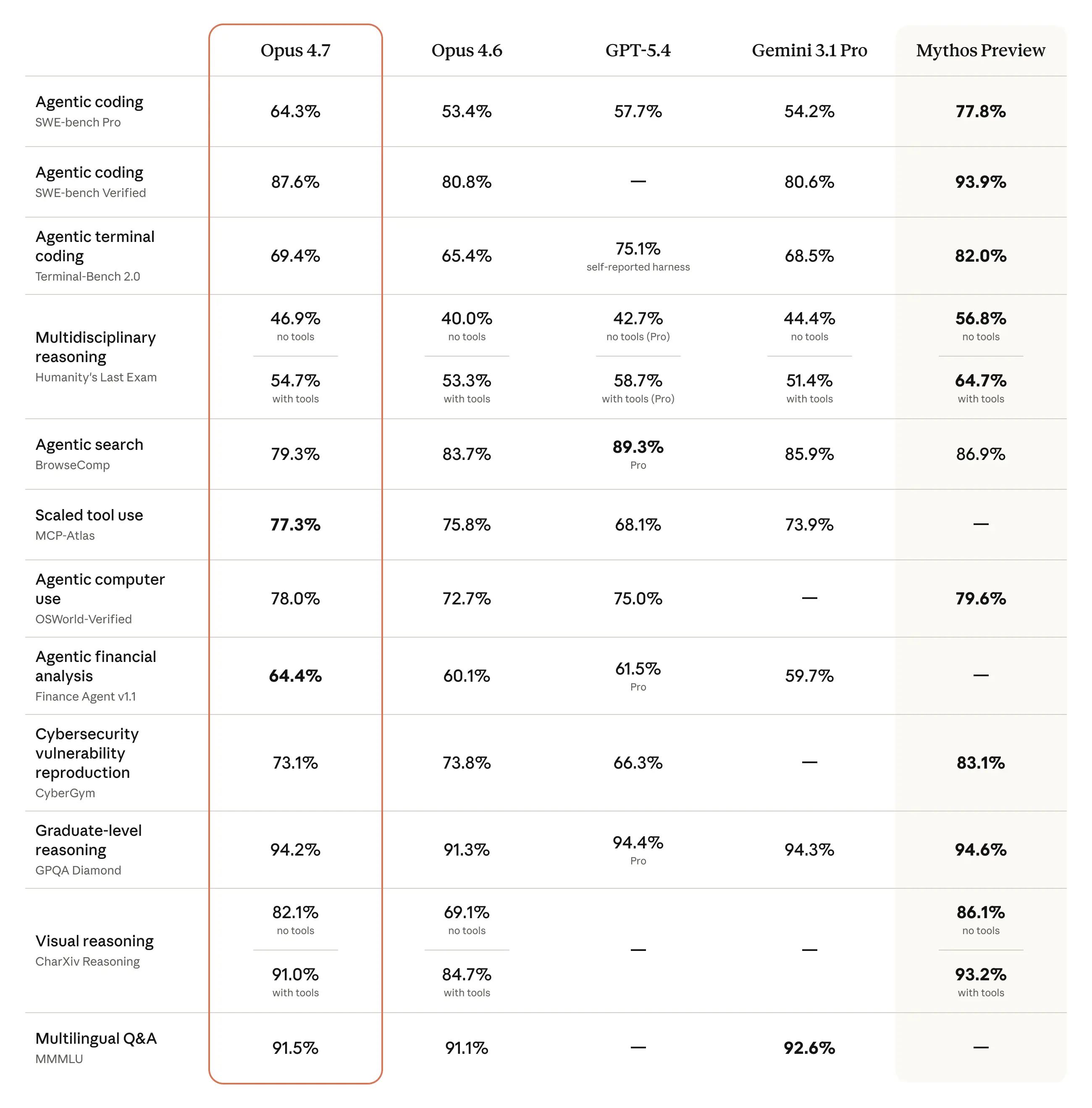
Opus 4.7 là flagship model tính đến thời điểm viết bài này. Anthropic cũng đang thử nghiệm hạn chế một mô hình mạnh hơn mang tên Claude Mythos Preview, nhưng Opus 4.7 vẫn dẫn đầu về benchmark công khai so với Opus 4.6.
Claude Opus 4.7 có gì mới so với Opus 4.6?
Opus 4.7 không chỉ mạnh hơn về điểm số - mà thực sự hữu ích hơn trong công việc thực tế. Dưới đây là ba cải tiến đáng chú ý nhất:
Khả năng lập trình và tự kiểm tra code
Đây là điểm nâng cấp nổi bật nhất. Trên benchmark Rakuten SWE-Bench production, Opus 4.7 giải quyết gấp 3 lần số lượng tác vụ so với Opus 4.6. Nguyên nhân: mô hình tích hợp cơ chế tự kiểm tra lỗi logic trước khi viết code, thay vì chỉ hoàn thành task rồi chờ phản hồi.
Cụ thể hơn trên các benchmark lập trình:
| Benchmark |
Opus 4.6 |
Opus 4.7 |
Cải thiện |
| CursorBench |
58% |
70% |
+12% |
| SWE-Bench Verified |
80.8% |
87.6% |
+6.8% |
| SWE-Bench Pro |
53.4% |
64.3% |
+10.9% |
| Rakuten SWE production |
Cơ bản |
Gấp 3x |
~+200% |
Ngoài ra, CodeRabbit ghi nhận Opus 4.7 tăng 10% recall phát hiện lỗi khó so với phiên bản trước - con số đáng kể với các đội dev đang dùng AI review code.
Xử lý hình ảnh độ phân giải cao
Opus 4.6 và các phiên bản Claude trước chỉ xử lý ảnh ở khoảng ~1 megapixel. Opus 4.7 nâng lên 2.576px cạnh dài (~3,75 megapixel) - tức gấp hơn 3 lần.
Điều này có nghĩa gì trong thực tế?
- Đọc được text nhỏ trong screenshot giao diện phức tạp
- Phân tích sơ đồ kỹ thuật, cấu trúc hóa học chi tiết
- Xử lý bằng sáng chế khoa học với hình ảnh độ nét cao
- Hỗ trợ screenshot agent hoạt động chính xác hơn
Benchmark XBOW visual acuity cho thấy mức nhảy vọt từ 54.5% lên 98.5% - tăng 44 điểm phần trăm. Trên Databricks OfficeQA Pro, lỗi phân tích tài liệu giảm 21%.
Cải thiện trong lĩnh vực tài chính và pháp lý
Opus 4.7 không chỉ mạnh về code. Trên Finance Agent Eval, mô hình đạt 0.813 (tăng từ 0.767 của Opus 4.6). BigLaw Bench ghi nhận 90.9% độ chính xác khi phân biệt các điều khoản pháp lý phức tạp - đây là chỉ số quan trọng với các doanh nghiệp dùng AI hỗ trợ công tác pháp chế.
Làm thế nào để truy cập và sử dụng Claude Opus 4.7?
Có 3 cách chính để dùng Opus 4.7, tùy nhu cầu và ngân sách:
Qua giao diện Claude.ai
Cách đơn giản nhất. Truy cập claude.ai, đăng ký tài khoản và nâng cấp lên gói Pro (20 USD/tháng) hoặc cao hơn (Max, Team, Enterprise). Sau đó chọn "Claude Opus 4.7" từ menu dropdown trong giao diện chat.
Lưu ý: Người dùng miễn phí có thể bị giới hạn hoặc không truy cập được Opus 4.7. Opus 4.7 hỗ trợ context window 1 triệu token và tính năng adaptive thinking.
Qua Anthropic API
Phù hợp cho developer muốn tích hợp vào ứng dụng. Tạo tài khoản tại console.anthropic.com, lấy API key và dùng model ID claude-opus-4-7.
Ví dụ Python cơ bản:
import anthropic
client = anthropic.Anthropic(api_key="your_api_key")
message = client.messages.create(
model="claude-opus-4-7",
max_tokens=1024,
messages=[{"role": "user", "content": "Phân tích đoạn code này"}]
)
print(message.content[0].text)
Giá API:
- Input: 5 USD/triệu token
- Output: 25 USD/triệu token
- Tiết kiệm qua prompt caching: lên đến 90%
- Batch processing: giảm thêm 50%
Qua nền tảng đám mây doanh nghiệp
Opus 4.7 có sẵn trên Amazon Bedrock, Google Vertex AI và Microsoft Foundry với cùng model ID và giá tương đương Anthropic. Phù hợp cho môi trường production cần tuân thủ quy định cao.
Claude Opus 4.7 phù hợp với ai?
Không phải mọi người đều cần dùng Opus 4.7. Đây là mô hình mạnh nhất trong dòng Claude công khai, đồng nghĩa với chi phí cao hơn. Dưới đây là gợi ý phân loại:
Nên dùng Opus 4.7 nếu bạn:
- Là lập trình viên làm việc với codebase phức tạp, cần review và sửa lỗi logic tự động
- Cần phân tích tài liệu kỹ thuật, sơ đồ, ảnh độ phân giải cao
- Triển khai agentic workflows dài hạn (automation, CI/CD pipeline)
- Làm việc trong lĩnh vực tài chính, pháp lý với yêu cầu chính xác cao
Có thể dùng Claude Sonnet thay thế nếu:
- Tác vụ chủ yếu là viết nội dung, trả lời câu hỏi thông thường
- Ngân sách API hạn chế
- Không cần xử lý hình ảnh phức tạp hoặc code dài
Một số tính năng mới đáng chú ý trong Opus 4.7
Ngoài cải tiến benchmark, Opus 4.7 đưa vào một số tính năng mới:
Effort level "xhigh": Cho phép chỉ định mức độ suy luận sâu nhất. Khi dùng effort="xhigh", mô hình kích hoạt adaptive thinking - tự điều chỉnh độ sâu suy luận theo độ phức tạp của bài toán. Phù hợp với tác vụ như tối ưu thuật toán, phân tích chiến lược hoặc debugging phức tạp.
Task budgets (beta): Cho phép giới hạn số token mà mô hình dùng trong một tác vụ - hữu ích để kiểm soát chi phí trong production.
/ultrareview trong Claude Code: Lệnh mới cho phép Opus 4.7 tự kiểm tra toàn bộ codebase trước khi báo cáo kết quả cuối cùng. Đây là tính năng trực tiếp tận dụng cơ chế tự xác minh mà mô hình được huấn luyện.
Tuân thủ prompt nghiêm ngặt hơn: Opus 4.7 tuân theo hướng dẫn theo nghĩa đen chặt chẽ hơn Opus 4.6. Điều này có nghĩa là prompt cũ của bạn có thể cho kết quả khác đi - cần review lại system prompt nếu đang migrate từ 4.6.
Đánh giá tổng thể: Opus 4.7 có đáng nâng cấp không?
Đối với lập trình viên và đội kỹ thuật: Câu trả lời gần như là có. Mức cải thiện 12% trên CursorBench, gấp 3 lần trên Rakuten SWE-Bench, và cơ chế tự kiểm tra code là những nâng cấp thực chất - không chỉ là điểm benchmark trên giấy.
Đối với doanh nghiệp dùng AI phân tích tài liệu: Khả năng thị giác tăng gấp 3 lần là lý do đủ mạnh để thử. Nếu doanh nghiệp đang xử lý nhiều tài liệu dạng ảnh, scan hoặc sơ đồ kỹ thuật, Opus 4.7 sẽ tạo ra sự khác biệt rõ rệt.
Đối với người dùng phổ thông: Nếu bạn không có nhu cầu coding phức tạp hay xử lý hình ảnh chuyên sâu, Claude Sonnet vẫn là lựa chọn hợp lý hơn về chi phí.
Một điểm cần lưu ý: vì Opus 4.7 tuân theo prompt nghiêm ngặt hơn, hãy test lại system prompt cũ trước khi chuyển sang phiên bản mới trong production.


 (1)_cr_400x210.png)





_cr_400x210.png)
